In the rapidly growing landscape of AI-powered applications, the ability to retrieve relevant information from large sets of data is more critical than ever. Whether you're building a chatbot, a search engine, or an intelligent document assistant, the foundation often lies in the retriever. This component bridges natural language queries and the right information.
In LangChain, retrievers are the backbone of intelligent querying. While many developers start with basic implementations, advanced applications demand more refined strategies. This post will explore 3 advanced strategies for retrievers in LangChain that push beyond standard search, optimizing accuracy, diversity, and relevance in how information is accessed. Let’s dive into these powerful techniques that can help you create smarter, more responsive AI systems.
1. Vectorstore as a Retriever: Precision at Scale
One of the most foundational yet highly effective techniques in LangChain is using vectorstores as retrievers. These enable semantic similarity searches, moving beyond simple keyword matching. Instead of finding exact phrases, they retrieve documents based on meaning—a huge leap for applications that rely on contextual understanding.
LangChain allows developers to easily convert a vectorstore into a retriever. What makes this method advanced isn’t just the use of embeddings but the flexibility it provides. You can adjust the search approach—for example, using Maximum Marginal Relevance (MMR) to ensure diversity in the results or setting thresholds to filter only the most relevant documents.
This method becomes especially useful when working with large datasets such as customer reviews, user feedback, or technical documentation. It empowers the system to understand the essence of a query and return content that aligns with intent, not just literal wording. Advanced tuning options like customizing search types and applying score thresholds allow developers to balance recall and precision, which is essential in building reliable, real-world applications.
2. MultiQueryRetriever: Enriching Retrieval through LLM-Driven Diversity
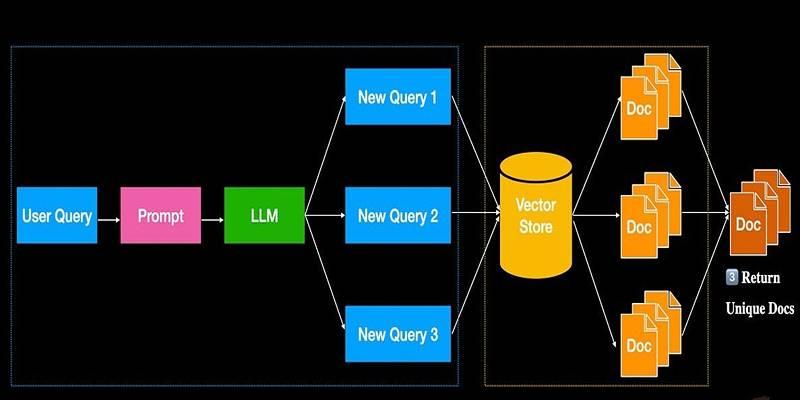
While vectorstores offer great precision, they can sometimes fall short when the user query is vague, complex, or phrased particularly. It is where the MultiQueryRetriever strategy shines. It enhances retrieval quality by generating multiple variations of a user's question using a large language model (LLM).
Instead of relying on one interpretation of a query, the MultiQueryRetriever leverages the language model to reframe the question from different angles. It enables the retriever to perform searches with multiple semantically distinct but related queries, broadening the scope of results.
The beauty of this approach lies in its ability to uncover documents that a single query might miss. Especially in domains with nuanced terminology or varied expressions—like product reviews, academic research, or technical specifications—this technique ensures that nothing valuable slips through the cracks.
Moreover, the strategy supports further customization. Developers can define how queries are generated using prompt templates and apply custom parsing to fine-tune what the LLM outputs. This level of control allows for domain-specific query expansion, making your retrieval system more intelligent and adaptable. By combining the power of vector search with LLM-guided query transformation, MultiQueryRetriever helps build systems that are both deep and wide in their understanding.
3. Contextual Compression: Extracting Only What Matters
When dealing with long-form documents—such as whitepapers, policy drafts, or research articles—retrieving an entire document based on a query can be inefficient and overwhelming. This is where the Contextual Compression strategy comes into play. It doesn’t just retrieve documents—it extracts and compresses relevant parts based on the query’s context.
Contextual Compression Retriever in LangChain works by integrating two components: a base retriever and a document compressor. The base retriever handles the initial document selection, while the compressor trims down each document, keeping only the content that directly addresses the query.
This technique offers several key benefits:
- Efficiency: Reduces the token load sent to the language model, saving computational resources.
- Relevance: Filters out noise and highlights the core information, improving the quality of the final response.
- Scalability: Enables working with large collections of documents without performance degradation.
It is particularly impactful in applications where precision is paramount—such as legal tech, medical research, or enterprise knowledge systems. By compressing content intelligently, you ensure that your language model focuses only on what truly matters.
It’s also worth noting that contextual compression can work hand-in-hand with LLMs that specialize in summarization or content extraction. It allows you to create end-to-end intelligent systems that both find and refine information with minimal manual intervention.
The Power of Customization: Build Your Retriever
While LangChain offers powerful built-in retrievers, it also gives you the freedom to create your own. Custom retrievers can be tailored to your application’s unique logic—for example, matching documents based on metadata, handling domain-specific rules, or integrating external APIs.
Creating a custom retriever involves extending a base interface and implementing logic to select relevant documents. Although simple in structure, this approach unlocks endless possibilities for domain adaptation. From sentiment-based filtering to geolocation-aware retrieval, custom retrievers help align the AI system's behavior with specific goals and audiences. This strategy is especially valuable for organizations working with proprietary data or needing to comply with regulations that affect how information is accessed and processed.
Choosing the Right Strategy

Each of the three strategies has its strengths. Here's a quick comparison to help you decide which is best for your needs:
Strategy | Best For | Key Benefit |
Vectorstore Retriever | General-purpose semantic search | Fast, accurate, and scalable |
MultiQueryRetriever | Complex, vague, or multi-faceted user queries | Broader coverage and deeper context |
Contextual Compression | Large, verbose documents with a low signal-to-noise ratio | Precision and efficiency |
In many cases, combining strategies yields the best results. For instance, a system might use MultiQueryRetriever to generate diverse queries and then apply Contextual Compression to extract only the most relevant parts from the results.
Conclusion
Retrievers in LangChain are not just about fetching documents—they’re about enabling smarter, more natural, and more effective interactions with data. As LLMs continue to evolve, the importance of intelligent retrieval only grows. It’s no longer enough to have access to information; the challenge is to deliver the right information at the right time, in the right format. By embracing advanced strategies like vectorstore-based retrieval, MultiQuery generation, and contextual compression, developers can build applications that don’t just respond—they understand.