As computer vision changes, advances in multimodal models—those that can understand both pictures and text—become more and more important. Among the most notable developments is Google’s SigLIP, a model that advances the foundation laid by OpenAI’s CLIP (Contrastive Language–Image Pre-training).
While CLIP proved revolutionary in matching images with corresponding textual descriptions using contrastive learning, SigLIP introduces an important shift in how these relationships are modeled. By replacing CLIP’s softmax-based contrastive loss with a sigmoid loss function, SigLIP not only maintains the core capabilities of CLIP but also enhances accuracy, scalability, and flexibility across a range of vision-language tasks.
Let’s explore the architecture of SigLIP, its improvements over CLIP, the role of the sigmoid loss function, performance insights, and its potential applications—all of which contribute to its significance in the field of image-text modeling.
A Refined Approach to Vision-Language Modeling
At its core, SigLIP is a model that creates dense embeddings for each medium and checks how similar they are to find pairs of images and text. The main idea is similar to CLIP, which pairs pictures with descriptions of them during training to make sure that their vector representations are in the right place.
However, where SigLIP truly innovates is in the way it evaluates the alignment of image-text pairs. CLIP uses a softmax function to compare all possible image-text combinations in a batch, assuming that each image has exactly one correct matching text. SigLIP breaks away from this restriction by introducing sigmoid loss, allowing each image-text pair to be evaluated independently.
Model Architecture: Familiar Yet Refined
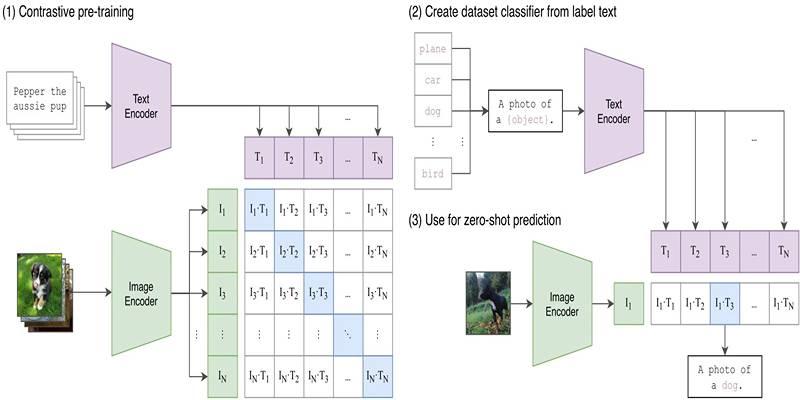
SigLIP follows a two-stream architecture similar to CLIP, with separate encoders for images and text. Both modalities are processed independently before their embeddings are compared. Here's a breakdown of its components:
Vision Encoder
SigLIP employs a Vision Transformer (ViT) as its image encoder. Images are first divided into patches, which are then linearly embedded and passed through transformer layers. This approach enables the model to learn spatial features and high-level visual patterns.
Text Encoder
Text input is handled by a Transformer-based encoder that converts words or sentences into dense vector representations. This textual embedding captures semantic meaning, allowing the model to connect words to corresponding visual features.
Embedding Alignment
After generating the embeddings for both image and text inputs, the model calculates similarity scores between them. These scores determine how well a given text matches a specific image or vice versa. It is at this stage that SigLIP’s use of sigmoid loss comes into play, allowing each pair to be assessed on its merit.
The Significance of Sigmoid Loss
The most critical distinction between CLIP and SigLIP is how they handle loss during training. In CLIP, softmax loss is used across batches of image-text pairs. It means that the model is forced to choose one correct match among several, even if multiple labels could be accurate—or none at all.
SigLIP replaces softmax with sigmoid loss, where each image-text pair is treated as a binary classification task. This method allows the model to assess every pair individually, removing the assumption that one correct match must exist within a batch.
This small change brings several advantages:
- Independent Pair Evaluation: Each image-text pair is evaluated on its own, which is more aligned with real-world scenarios where multiple labels might be correct.
- Better Handling of Ambiguity: Unlike CLIP, SigLIP doesn’t overcommit to a false match when the correct label isn’t present.
- Improved Zero-Shot Performance: By not forcing a single “best” match, SigLIP performs better in zero-shot classification, where label options may be unpredictable or incomplete.
Performance and Scalability
One of SigLIP’s strengths lies in how it scales across different model sizes and training batch sizes. Because it does not depend on a global normalization step across the batch (as softmax does), it can scale more flexibly without deteriorating training quality.
In performance benchmarks, SigLIP has shown:
- Higher accuracy in zero-shot classification tasks
- Lower prediction error when the correct label is missing
- More stable training behavior across different configurations
Ongoing experiments with larger models like SoViT-400m indicate that SigLIP’s architecture is well-suited for scaling up while maintaining or improving performance.
Practical Use: How SigLIP Handles Inference
One of the key features of SigLIP is its ease of inference, especially when used through libraries like Hugging Face Transformers. Without getting into implementation details, here's a simplified explanation of the process:
- Image Input: The user supplies an image, either by upload or URL.
- Text Input: A list of potential text labels or descriptions is provided.
- Model Processing: The model calculates the similarity between the image and each text label.
- Output: Each label is scored independently. The label with the highest similarity score is considered the most relevant.
This independence in scoring reflects the benefits of the sigmoid loss function. When the correct label is not present, the model assigns low probabilities across the board instead of falsely favoring one label, as in softmax-based models like CLIP.
SigLIP vs. CLIP: A Functional Comparison

To truly appreciate SigLIP, it's important to highlight the differences in how it behaves compared to CLIP during inference.
In CLIP:
- Even if none of the text labels match the image, it will still pick one with high confidence.
- It can lead to false positives in classification tasks.
In SigLIP:
- If none of the text labels are relevant to the image, the model returns low probabilities for all.
- It provides a more accurate reflection of uncertainty.
This difference plays a vital role in applications where precision is critical, such as content filtering, medical imaging, or product tagging. A model that knows when it doesn’t know is often more valuable than one that guesses confidently and incorrectly.
Conclusion
Google’s SigLIP represents a meaningful progression in the evolution of vision-language models. While it builds on the successful architecture of CLIP, its introduction of the sigmoid loss function marks a pivotal improvement in how image-text relationships are modeled and understood. By treating each image-text pair independently, SigLIP improves precision, handles ambiguity better, and scales effectively with large data volumes.