Process and handling embeddings at scale is very important in this era of growing data and needs for faster, scalable, and smarter apps. Traditional embedding techniques, while effective in small-scale contexts, begin to show cracks when applied to large documents, multi-modal data, or resource-constrained environments.
Enter vector streaming—a new feature introduced in the EmbedAnything framework designed to address these limitations. What makes it even more powerful is its implementation in Rust, a systems programming language celebrated for its speed, memory safety, and concurrency support.
This post delves into how vector streaming, powered by Rust, brings memory-efficient indexing into practical use and why this is a major step forward for embedding pipelines and vector search applications.
Understanding the Problem with Traditional Embedding Pipelines
Most traditional pipelines for generating vector embeddings from documents follow a two-step process:
- Chunking: Extracting and splitting content from source files into manageable pieces.
- Embedding: Feeding these chunks into an embedding model in batches.
This method works adequately with small datasets. However, as the number of files grows or the models become larger and more sophisticated—especially when multi-vector embeddings are involved—several performance and memory-related problems emerge:
- All chunks and embeddings are held in memory until the entire process is completed.
- Synchronous execution wastes time while waiting for chunks to finish before embedding begins.
- Embedding at scale requires high RAM, leading to resource bottlenecks or system slowdowns.
When applied to real-world datasets with high dimensionality or image and text modalities, this process becomes inefficient and unsustainable.
Vector Streaming: The Rust-Powered Solution

To overcome these challenges, EmbedAnything introduces vector streaming—a new architecture that leverages asynchronous chunking and embedding, built using Rust’s concurrency model.
At its core, vector streaming reimagines how the embedding process flows. Instead of treating chunking and embedding as isolated, sequential operations, it streams data between them using concurrent threads.
Here’s how it works:
- A thread asynchronously chunks the input data and pushes it to a buffer.
- As the buffer fills, another thread embeds the chunks, maintaining a smooth flow.
- Once embeddings are created, they are sent back to the main thread, which forwards them to the vector database.
- At every stage, data is erased from memory once it’s processed, minimizing memory usage.
It eliminates idle time and makes use of available computing resources more effectively, all while keeping memory overhead under control.
Why Rust Makes It Possible?
Rust is an ideal language for building performance-critical, concurrent systems. The choice to implement vector streaming in Rust wasn’t incidental—it was strategic. Rust offers:
- Zero-cost abstractions for performance that rivals C/C++.
- Strong memory safety without needing a garbage collector.
- Native concurrency support, allowing multiple threads to operate safely.
Using Rust’s MPSC module, vector streaming enables message-based data flow between threads. The embedding model doesn’t wait for all chunks to be created—instead, it starts embedding as soon as data becomes available.
Solving Real Bottlenecks in Embedding Workflows
With traditional synchronous pipelines, the more documents you have, the more memory and time the system demands. And when multi-vector embedding is involved—where multiple vectors are generated per chunk—the challenge compounds.
Vector streaming addresses these issues head-on:
- No need for high-RAM systems: Since data is processed and discarded in real-time, only a small buffer stays in memory.
- Eliminates idle phases: Embedding begins as soon as chunks are available, reducing wait times.
- Adaptable to multiple modalities: Works equally well for images, text, and other data formats.
- Supports large-scale embedding: Makes it feasible to embed huge datasets without resource strain.
The result is a more scalable and efficient pipeline for developers, researchers, and engineers working on AI-driven applications.
How It Integrates with Vector Databases Like Weaviate?
Once embeddings are generated, they need to be indexed for search and retrieval. Vector streaming integrates cleanly with databases such as Weaviate, offering a smooth hand-off from embedding to storage.
The architecture includes a database adapter that handles:
- Connection setup
- Index creation
- Metadata conversion
- Batch upserts of vectors
This modularity allows developers to plug and play with different vector databases without modifying the core embedding logic.
Configuration and Control
Vector streaming in EmbedAnything is designed with flexibility in mind. Developers can customize the following:
- Embedding model: Choose between local or cloud-hosted models, including image-based models like CLIP.
- Chunk size: Define how large each chunk should be.
- Buffer size: Control how many chunks are stored and processed at a time.
These parameters give full control over performance tuning and allow you to optimize based on your hardware constraints. Ideally, the buffer size should be as large as your system can support for maximum throughput.
Benefits of Vector Streaming for Memory-Efficient Indexing
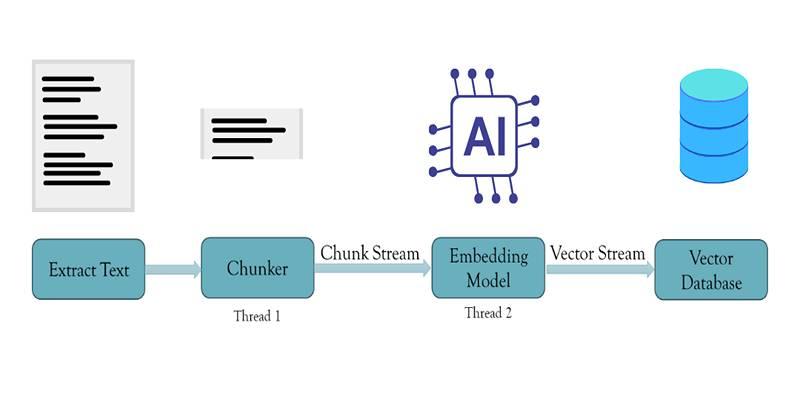
The impact of vector streaming goes beyond theoretical optimization—it brings tangible performance gains and operational simplicity for developers, engineers, and researchers. Let’s take a closer look at the key benefits:
Drastically Reduced Memory Usage
Traditional pipelines require loading all data into memory before processing. In contrast, vector streaming keeps only a small buffer of chunks and embeddings in memory at a time.
Parallel Processing for Faster Results
Chunking and embedding run concurrently, meaning there’s no idle time between stages. Embedding can begin as soon as the first few chunks are ready, reducing total execution time and increasing pipeline throughput.
Simplified Integration
With modular adapters for vector databases and clean API design, embedding and indexing are no longer separated by complex glue code. The flow from raw data to vector database is seamless and requires minimal effort from the developer.
It reinforces vector streaming as a Rust-powered solution for truly memory-efficient indexing.
Conclusion
Vector streaming with Rust offers a modern, efficient, and developer-friendly solution to the age-old problems of memory bloat and inefficiency in embedding pipelines. With its smart use of concurrency and stream-based design, it enables fast, low-memory processing of large-scale data—ideal for real-world applications in search, recommendation, and AI. As data grows and embedding pipelines become more integral to modern systems, tools like EmbedAnything, combined with Rust’s performance, promise to change how we think about large-scale indexing.