In the world of large language models (LLMs), innovation is often driven by the need for better efficiency, scalability, and the ability to handle longer context windows. The release of Jamba 1.5, developed by AI21 Labs, introduces a cutting-edge advancement in this space: the hybrid Mamba-Transformer architecture.
Jamba 1.5 is designed not just to handle natural language tasks but to do so with enhanced memory management, speed, and context understanding. It achieves this by combining the structured state space modeling (SSM) capabilities of Mamba with the global attention features of the Transformer.
This hybrid architecture allows it to process up to 256,000 tokens—an industry-leading context window in open-source models. This post dives into what makes Jamba 1.5 unique, how its hybrid architecture functions, and why it matters for the future of AI development and deployment.
What Is Jamba 1.5? A Hybrid Language Model
Jamba 1.5 is an instruction-tuned language model that merges two architectures: the traditional Transformer and the more recent Mamba SSM. Unlike models that rely solely on attention mechanisms, Jamba leverages both state space models and attention layers, offering improved performance across long-context tasks and low-latency environments.
Jamba 1.5 is available in two main variants:
- Jamba 1.5 Large: 94 billion active parameters (398B total)
- Jamba 1.5 Mini: 12 billion active parameters (52B total)
Despite their differences in size, both models benefit from the same hybrid foundation that allows them to perform diverse NLP tasks—from summarization and translation to question answering and text classification—with exceptional efficiency.
The Hybrid Mamba-Transformer Architecture Explained
The core of Jamba 1.5’s strength lies in how it merges two distinct design philosophies into a hybrid architecture. Here's how this architecture is structured:
1. Base Composition
Jamba 1.5 is built using 9 modular blocks, each containing 8 layers. These layers follow a 1:7 ratio—meaning for every Transformer attention layer, there are seven Mamba layers. It allows the model to benefit from the long-range, low-memory characteristics of Mamba while retaining the attention capabilities of Transformer layers for global pattern recognition.
2. Mixture-of-Experts (MoE) Module
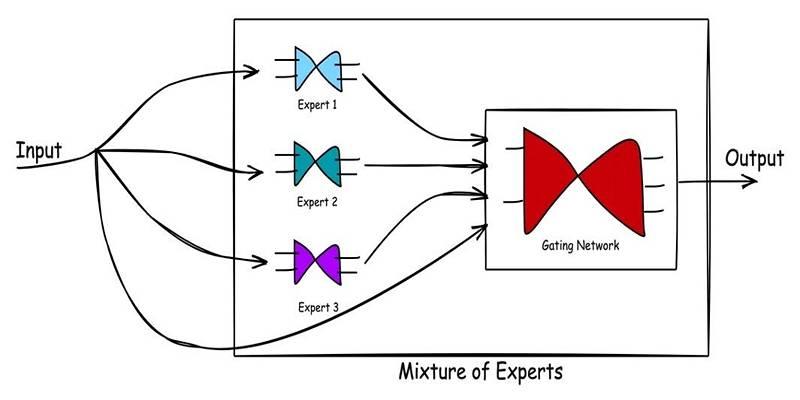
The architecture integrates a Mixture-of-Experts (MoE) mechanism. It consists of 16 expert models, of which only the top 2 are activated per token. It enables dynamic routing and ensures specialized processing for different input types, boosting performance while keeping computation efficient.
3. Quantization with ExpertsInt8
To make the model more memory-efficient, Jamba 1.5 uses ExpertsInt8 quantization for both its MoE and MLP layers. It allows it to operate in 8-bit precision without compromising on throughput, reducing memory load significantly—particularly important for real-time or resource-constrained deployments.
4. Attention and Context Handling
With 64 attention heads for queries and 8 key-value heads, Jamba 1.5 maintains a high attention capacity. Most importantly, it supports a context window of 256K tokens, which is currently the largest among publicly available open-source models. Traditional Transformers struggle with long sequences due to memory-hungry key-value (KV) caching. Jamba addresses this with architectural optimizations that reduce KV cache memory while preserving sequence integrity.
5. Activation Stabilization with Auxiliary Losses
To ensure consistent performance across extremely deep architectures and long sequences, Jamba 1.5 incorporates auxiliary loss functions that help stabilize activation magnitudes. When combining Mamba and Transformer layers, variations in how information flows through the network can lead to unstable gradients or vanishing activations.
Why the Hybrid Architecture Matters?
The hybrid architecture of Jamba 1.5 addresses some of the biggest limitations of earlier LLMs:
- Memory Efficiency: Mamba’s state-space design dramatically reduces the memory overhead that comes with handling long sequences in Transformers.
- Context Length: By supporting 256K tokens, Jamba 1.5 can model entire books, research papers, or multi-turn conversations without truncation.
- Dynamic Specialization: MoE allows the model to selectively engage different sub-networks, improving quality without a full increase in compute cost.
- Faster Inference: The balance of fewer attention layers and more Mamba layers results in lower latency for processing inputs.
This combination of advantages makes the model especially suitable for high-performance NLP tasks across domains like healthcare, legal, academic research, and customer service automation.
Efficiency and Hardware Compatibility
One big concern with modern LLMs is whether they can actually run efficiently on real-world hardware. Many models demand multiple GPUs and expensive infrastructure. Jamba 1.5 is designed to be more accessible.
- It supports Flash Attention and Paged Attention for faster inference.
- It is optimized for single-GPU inference using DeepSpeed and vLLM frameworks.
- Because Mamba layers are lighter, memory consumption is lower than pure Transformer models.
It makes Jamba 1.5 a great option for startups, independent developers, and small businesses looking to use powerful AI without huge infrastructure costs.
Model Variants and Accessibility

AI21 Labs has released two publicly accessible versions of Jamba 1.5:
- Jamba 1.5 Mini (12B): Lightweight, accessible for local or low-compute environments.
- Jamba 1.5 Large (94B): High-capacity model for demanding enterprise use cases.
Both are instruction-tuned and multilingual, supporting nine languages: English, Portuguese, Hebrew, German, Italian, Dutch, Spanish, Arabic, and French.
Developers and researchers can access Jamba 1.5 via:
- AI21 Studio API
- Hugging Face Model Hub
- AI21’s Web Chat Interface
It can also be integrated into applications using Python with simple API calls, enabling usage in platforms like chatbots, text analytics tools, and content generation services.
How Jamba 1.5 Compares to Standard Transformers
Feature | Traditional Transformers | Jamba 1.5 Hybrid Model |
|---|---|---|
Architecture | Attention-only | Mamba + Transformer |
Context Length | Typically 2K–32K tokens | Up to 256K tokens |
Memory Usage | High | Lower with Mamba and Int8 |
Latency | Moderate to High | Lower (fewer attention layers) |
Specialized Computation (MoE) | No | Yes (dynamic routing) |
Quantization | Optional (often FP16) | Built-in ExpertsInt8 |
Conclusion
Jamba 1.5 represents a significant leap forward in large language model architecture. By merging the Transformer’s powerful attention mechanism with the Mamba model’s ability to handle long sequences efficiently, AI21 Labs has created a model that sets a new benchmark in open-source LLMs. Its hybrid structure is more than just a technical achievement—it’s a solution to real-world challenges in scaling language models. With 256K context support, modular MoE components, and efficient quantization, Jamba 1.5 is optimized for both performance and practicality.











